Bandwidth와 Latency
Bandwidth란?
네트웍에서 이용할 수 있는 신호의 최고 주파와 최저 주파수의 차이를 말한다.일반적으로는 통신에서 이용 가능한 최대 전송속도, 즉 정보를 전송할 수 있는 능력을 뜻하며, 그 기본 단위로는 bps를 사용한다. - terms.co.kr
기본 단위인 Bytes Per Seconds 를 생각해 보면 단위 시간 당 전송할 수 있는 데이터의 최대양을 말한다.
Latency란?
네트웍에서의 latency는 delay와 비슷한말로서, 하나의 데이터 패킷을 한 지점에서 다른 지점으로 보내는데 소요되는 시간을 표현한 것이다. - terms.co.kr
다시말해서 신호를 보낸 지점에서 부터 받는 지점까지의 이동 속도라고 볼 수 있다.
위의 두 요소는 모두 전송속도에 영향을 미치지만 서로 독립적이다. Bandwith가 높다면 시간당 전송 데이터의 양이 많아지므로 전송을 시작하고 끝내기까지의 소요시간이 줄어들 수 있지만, 데이터 통신에서는 서로 응답을 주고 받아야 하므로, latency가 크다면, 상대방으로부터 응답이 돌아오기까지의 시간이 오래 걸리게 된다. 따라서 데이터를 보내놓고 응답을 기다리는 대기시간이 길어져 최종적으로는 느린 성능의 결과를 초래하게 된다.
반대로 latency가 작다면 응답을 바로 받을 수는 있지만, bandwidth가 작다면 한 번 데이터를 전송하는데 걸리는 시간이 길어져 대기시간 없이 바쁘게 일해도 한참이 걸리는 결과를 초래하게 된다.
웹 자원 캐시
웹 리소스는 서버에서 받아오는데 비용이 들기때문에, 클라이언트 쪽 컴퓨터에 캐시를 해두면 동일한 데이터를 여러번 받아오는 비용을 절감할 수 있다. 이런 동작을 하기 위해서는 서버쪽 데이터가 변경이 되었는지, 캐시를 얼마나 유지해야 하는지 등의 정보가 필요하다. http://example.com에 접속하면서 개발자도구의 network 기능을 이용해서 이러한 과정이 이루어지는 순서를 살펴보면,
-
최초의 평범한 GET 요청의 헤더
GET / HTTP/1.1 Host: example.com Connection: keep-alive Cache-Control: max-age=0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.107 Safari/537.36 Accept-Encoding: gzip, deflate, sdch Accept-Language: ko,en;q=0.8 -
응답
HTTP/1.1 200 OK Accept-Ranges: bytes Cache-Control: max-age=604800 Content-Type: text/html Date: Wed, 29 Jul 2015 07:34:25 GMT Etag: "359670651" Expires: Wed, 05 Aug 2015 07:34:25 GMT Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT Server: ECS (cpm/F9D5) X-Cache: HIT x-ec-custom-error: 1 Content-Length: 1270여기서 자세히 살펴볼 항목은 다음과 같다.
- Expires: Wed, 05 Aug 2015 07:34:25 GMT
클라이언트가 캐시를 유지할 최대 간을 지정해준다. - Cache-Control: max-age=604800
클라이언트가 캐시를 유지할 최대 시간을 초 단위로 상대적으로(캐시된 시간 기준으로)지정해준다. - Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
리소스가 마지막으로 수정된 시간 - Etag: “359670651”
해시 함수 등을 통해 생성된 리소스의 Finger Print. 클라이언트는 Etag을 비교해서 리소스가 변경되었는지 여부를 알아낼 수 있다.
이러한 response를 받고 나면 클라이언트는 최대 Cache-Control이나 Expires에 따라 최대 21600초 동안 해당 리소스를 캐시 하게 된다. 사용자가 그 이후에 새로 고침등을 통해서 같은 리소스에 접근 요청을 하면 브라우저는 로컬에 캐시가 있으므로 다음과 같이 Conditional Get Request 를 보내게 된다.
- Expires: Wed, 05 Aug 2015 07:34:25 GMT
-
Conditional Get Request
GET / HTTP/1.1 Host: example.com Connection: keep-alive Cache-Control: max-age=0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.107 Safari/537.36 Accept-Encoding: gzip, deflate, sdch Accept-Language: ko,en;q=0.8 If-None-Match: "359670651" If-Modified-Since: Fri, 09 Aug 2013 23:54:35 GMT- If-Modified-Since: Fri, 09 Aug 2013 23:54:35 GMT
위의 2번에서 Last-Modified 시간을 보낸다. - If-None-Match: “359670651”
위의 2번에서 Etag 항목에 있던 finger print
즉, 특정시간 이후에 수정이 있었거나, 이전에 받았던 리소스의 finger print와 일치하지 않을때만 리소스를 다시 전송하라는 요청이다. 이러한 요청을 받게 되면 서버에서는 클라이언트가 이미 Last-Modified 시간에 리소스를 받아갔며 그 이후에 서버쪽 리소스가 변경되지 않았다면 동일한 리소스를 가지고 있을 것임을 알 수 있다. 혹시 이 시간 정보가 어긋나더라도 If-None-Match 에 들어있는 Etag를 확인하면 서로 같은 리소스를 가지고 있는지 확인 가능하다. 이 정보들을 확인해서 클라이언트가 캐시를 업데이트할 필요가 없다고 판단되면 서버는 리소스를 보내지 않고 다음과 같은 status code를 통해서 클라이언트가 미리 캐시된 정보를 사용하도록 할 수 있다.
- If-Modified-Since: Fri, 09 Aug 2013 23:54:35 GMT
-
HTTP 304 Not Modified
HTTP/1.1 304 Not Modified Accept-Ranges: bytes Cache-Control: max-age=604800 Date: Wed, 29 Jul 2015 07:35:45 GMT Etag: "359670651" Expires: Wed, 05 Aug 2015 07:35:45 GMT Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT Server: ECS (cpm/F9D5) X-Cache: HIT x-ec-custom-error: 1이러한 응답을 받게 되면 브라우저는 로컬에 캐시되었던 리소스를 이용해서 웹페이지를 렌더링하게 되고, 동일한 리소스의 중복 전송을 방지하므로써 네트워크 자원을 절약하게 된다.
HTTP 200 Ok (from cache)
이 경우는 브라우저에서 서버쪽으로 요청을 보내지 않고 cache에서 직접 resource를 가져온 후 200 처리한 경우이다. HTTP spec 에 정의된 동작은 아니며 각 브라우저 엔진별 동작에 따라 처리된다. Webkit 엔진의 경우 다음과 같이 처리하는 것으로 알려졌다.
- 일반적인 링크나 주소창을 통한 접근 : 서버에 요청을 보내지 않고 200(from cache) 처리
- 새로고침할 경우 : Conditional Get Request
- 강력 새로고침 또는 개발자 도구 Network 탭에서 Disable Cache 선택시 : 서버에 완전히 새로운 데이터를 요청하며 이때 헤더에
Cache-Control: no-cache를 포함에서 요청한다.
Expires vs Cache-control
Expires는 캐시가 만료될 날짜를 지정하게 된다. 날짜는 헤더를 살펴보면 알 수 있듯이, 다음과 같이 로컬 시간이 아닌 그리니치 표준시를 입력해야 한다.
Expires: Fri, 30 Oct 1998 14:19:41 GMT
따라서 자주 변경되지 않는 static resource에 대해서 지정하기에 좋고, 특히 특정 날짜나 시간에 업데이트 될 리소스에 대해서 지정할 때 유용하다. 하지만 절대적인 날짜를 지정하기 때문에 몇몇 단점을 가지고 있다.
- 서버측 시간과 클라이언트측 시간이 일치해야 정확히 작동한다.
- 서버에서 리소스가 업데이트 된 다음에 Expires 헤더를 적절히 업데이트하는 것을 잊어버리면 해당 리소스는 지정된 날짜가 지난 이후에는 더이상 캐시되지 않는다.
Expires 에 비해, Cache-Control 은 HTTP 1.1 에서 새롭게 추가된 class 이다. Expires 가 지정된 날짜를 정해서 캐시를 컨트롤 하기 때문에 가지는 몇몇 단점을 보완하기 위한 추가 기능들이 있다. 다음은 Cache-Control 에 사용 가능한 항목들의 목록이다.
- max-age=[seconds] : 리소스 요청 시에 대해 상대적인 캐시의 유지 기간
- s-maxage=[seconds] : 위와 동일, 프록시 캐시등 공유캐시에만 적용됨
- public : 인증된 응답정(authenticated response)을 캐시 가능하게 설정
- private : 한 명의 사용자에게만 캐시 가능. 예를 들어 브라우저에는 가능하지만 프록시 캐시에는 캐시할 수 없음.
- no-cache : 캐시된 데이터를 사용하기 전에 서버에 매번 반드시 확인해야 함.
- no-store : 어떤 경우에도 로컬에 복사본을 저장하지 않음.
- must-revalidate : HTTP1.1 캐시는 특정 조건에서 헤더의 지시를 무시할 수도 있다. 이 항목은 이런 동작을 막고 어떤 경우이든 헤더에 지시된 동작을 따르도록 강제한다.
- proxy-revalidate : must-revalidate와 동일 하지만 프록시 캐시에 적용된다.
참고 : 꿀벌개발일지 :: 웹킷의 리소스 캐시 동작, RFC2616, Caching Tutorial for Web Authors and Webmasters
HTTP 압축
앞서 살펴본 최초 request Header를 다시 살펴보자. 다음과 같은 필드를 살펴볼 수 있다.
Accept-Encoding: gzip, deflate, sdch
이 부분은 클라이언트측 프로그램이 위와 같은 형식의 압축된 데이터를 받아서 디코딩 할 수 있다는 것을 알려준다.
서버에서 네트워크 부하를 줄이기 위해 데이터를 압축하고자 할 경우, 클라이언트에서 압축 해제 가능한 방식으로 보내야 하기 때문에 이 정보가 필요하다.
클라이언트에서 처리 가능한 방식을 확인한 후에는 서버에서 이 중에 하나를 골라서 데이터를 압축해서 보낼 수 있다. 이때 어떤 방식으로 압축했는지를 알려줘야 클라이언트가 제대로 압축해제할 수 있다. 이를 표시해주는 필드가 Content-Encoding 이다.
다시 위의 2번에 있는 response Header 를 살펴보면, 해당 항목이 없다. 따라서 example.com은 데이터를 압축해서 보내지 않는 것으로 판단할 수 있다.
데이터 압축을 실행하는 사이트에 접속해서 responsse header를 살펴보면 Content-Encoding: gzip 를 확인할 수 있다. gzip을 통해서 데이터를 압축해서 보낸 것이다.
전송량 비교
실제 압축에 따른 효용성이 있는지 확인하기 위해서 테스트를 진행했다. 테스트는 일정한 결과를 위해서 비교적 정적인 페이지인 네이버 사전 메인 에서 실행하고, ‘캐시 비우기 및 강력 새로고침’ 기능으로 캐시에 따른 차이를 없앴다.
압축시
다음은 네이버 사전 메인화면의 html 내용에 대한 response header 이다.
HTTP/1.1 200 OK
Date: Wed, 29 Jul 2015 09:31:14 GMT
Server: Apache
Cache-Control: no-cache
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Cache-Control: no-store,must-revalidate
Vary: Accept-Encoding,User-Agent
Content-Encoding: gzip
X-XSS-Protection: 0
Content-Length: 22358
Connection: close
Content-Type: text/html;charset=UTF-8
Content-Encoding: gzip 를 확인할 수 있다. gzip을 통해서 데이터를 압축해서 보낸 것이다.
이때 총 받은 데이터 양을 보면 303KB 를 전송받았다.
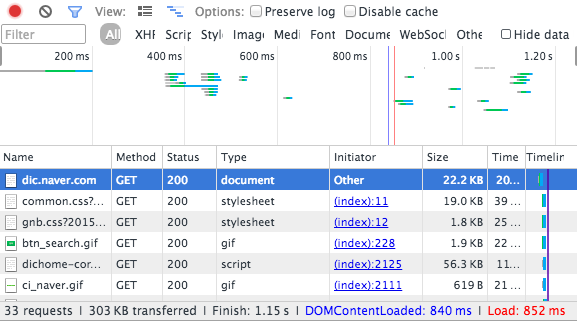
압축 안할 시
이번에는 크롬 익스텐션 ModHeader 를 통해서 header에서 Accept-Encoding 를 빼고 다시 요청을 보내서 header를 살펴보면
HTTP/1.1 200 OK
Date: Wed, 29 Jul 2015 09:32:23 GMT
Server: Apache
Set-Cookie: JSESSIONID=34E0729F86161DDEBE7D809C6C33A7DB; Path=/
Cache-Control: no-cache
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Cache-Control: no-store,must-revalidate
Vary: Accept-Encoding,User-Agent
X-XSS-Protection: 0
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html;charset=UTF-8
Content-Encoding 항목이 없는것을 확인할 수 있다. 클라이언트 측 브라우저가 gzip을 해제할 수 없는 것을 확인하고 압축 없이 데이터를 그대로 보낸 것이다.
이때 총 전송된 용량을 살펴보면, 967KB 가 전송되어, 압축된 데이터보다 많은 트래픽이 발생한 것을 확인할 수 있다.
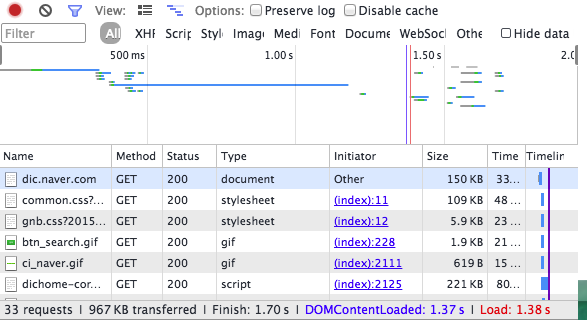
실제 운용에서의 효용성
실제 서버에 데이터 압축을 적용할 때 고려할 것은 두 가지이다.
-
실제로 압축을 할 때 용량이 줄어드는가?
이미지나 동영상 등 어떤 파일 포맷은 이미 충분히 압축되어 있을 수 있다. 이런 파일들은 압축시 역으로 용량이 증가할 수 있다. 특히 글꼴 파일의 경우, ttf(트루타입), otf(오픈타입) 글꼴들은 압축이 필요하지만, woff(웹 오픈타입)의 경우, 이미 압축이 되어 있으므로, 압축시 역으로 용량이 증가하거나 용량 감소 효율이 적다. 이미지 파일의 경우, bmp 포맷 이외의 모든 이미지 파일들은 이미 압축된 상태이므로 재 압축시 효율이 떨어진다. -
압축시 발생하는 부하는 크지 않은가?
실제로 서버를 운영할 시에는 데이터를 전송하는 과정 뿐 아니라, 압축하는 과정에서도 서버 부하를 가져온다. 매 접속시마다 자주 변경되는 데이터라면 매번 다시 압축해서 전송하는 과정에서도 상당한 부하가 발생할 것이다.따라서 자주 변경되지 않는 정적인 리소스나, 서버측 렌더링이 사전에 완료되어 캐시가 가능한 리소스는 압축해서 전송하고 변경이 자주 일어나는 데이터는 비압축으로 전송하면 성능 최적화에 더 도움이 될 것으로 보인다.
참고자료 : HTTP 압축 (1) : 성능 향상을 위한 다른 접근 기법,How To Optimize Your Site With GZIP Compression, New Gzip Settings and Deciding What to Compress,
HTTP Connection
HTTP 통신에서 서버와 클라이언트는 connection 을 맺고 데이터를 전송하게 된다. 하나의 웹페이지를 렌더링하기 위해서는 html 내용뿐 아니라 여기에 로딩되는 수많은 자원들이 필요하다. 그러기 위해서는 수많은 connection을 맺고 끊어야 하는데 이 과정에서 많은 오버헤드가 발생한다. 이를 줄이기 위한 방법들은 다음과 같다.
parallel Connection
HTTP는 서버와 클라이언트 간에 여러개의 connection을 수립할 수 있도록 한다. 따라서 최초의 html 내용을 로드 한다음에는 그 안에 있는 리소스들을 차례로 요청하는 것이 아니라 한번에 많은 connection을 만들어서 동시에 전송할 수 있다. 하나의 connection이 네트워크의 bandwidth를 전부 활용하지 못할 경우, 여러개의 connection을 활용하게 되면 bandwith를 좀더 효율적으로 활용할 수도 있다. bandwidth가 충분하지 않더라도, 최소한 리소스가 하나씩 하나씩 로딩되지 않고 동시에 로딩되므로 사용자에게 좀더 빠르게 내용을 탐색할 수 있는 기회를 제공한다.
persistent Connection
위와 같은 parallel Connection 을 사용한다 하더라도, 여전히 하나의 리소스당 하나의 connection을 수립하므로, connection 수립에 따른 오버헤드는 여전하다. 각 리소스의 전송을 위해서는 최초에 3way-handshaking을 통해서 connection 수립하게 되는데 세차례나 데이터의 왕복이 이루어져야 하므로 bandwidth가 충분한 상황에서도 최소한 latency * 3 의 시간이 소요된다. 또 이에 따른 소켓당 포트, 메모리등 시스템 자원의 낭비도 심하게 된다.
이를 개선하기 위해 HTTP 1.1 에서는 keep-alive 기능을 도입하게 된다. HTTP header에 다음과 같은 필드를 통해서 설정할 수 있다.
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
위와 같이 설정하면, Connection을 Keep-Alive 방식으로 수립하게 되고, 전송이 끝난 후 아무런 응답이 없어도 5초 동안은 connection을 유지하게 된다. 이 시간 안에 새로운 request가 오면 connection을 종료하지 않고 유지하며 계속적으로 response를 보낸다. 이때 max에 설정된 대로 최대 100개의 request에 대한 응답을 처리하고 connection을 닫게 된다. 이러한 연결 방식은 아래와 같이 진행된다.
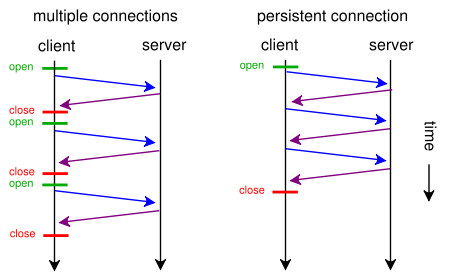 출처 : HTTP Pipelining: A security risk without real performance benefits
출처 : HTTP Pipelining: A security risk without real performance benefits
위 이미지와 같이 하나의 connection을 수립하고 이를 통해서 여러개의 리소스를 전송할 수 있다면 효율이 훨씬 좋게 된다.
persistent Connection을 사용하지 않으려면 아래와 같이 필드를 설정하면 된다.
Connection: close
pipeline Connection
위의 persistent_connection 모식도를 보면, 하나의 요청에 대한 응답이 끝난 후 다음 요청을 보내고 다시 받는 것을 반복하고 있다. 각 요청과 응답 사이를 자세히 보면, 서버측과 클라이언트측 모두 아무 일도 하지 않고 있는 대기시간이 존재한다. 이는 네트워크에서 발생하는 latency 때문인데, 다음 그림과 같이 요청에 대한 응답을 굳이 기다리지 않고 연속적으로 요청을 보낸다면 이러한 대기시간을 줄일 수 있다.
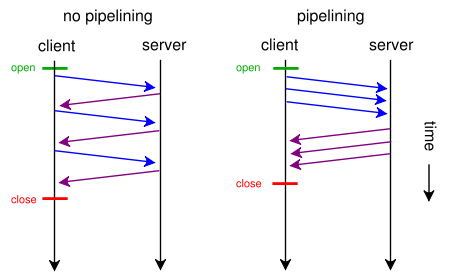 출처 : HTTP Pipelining: A security risk without real performance benefits
출처 : HTTP Pipelining: A security risk without real performance benefits
RFC2616에 따르면
A client that supports persistent connections MAY “pipeline” its requests (i.e., send multiple requests without waiting for each response). A server MUST send its responses to those requests in the same order that the requests were received.
persistent connections을 지원하는 클라이언트는 응답을 기다리지 않고 요청을 여러개 보낼 수 있으며 서버는 반드시 요청을 받은것과 같은 순서로 응답해야만 한다.
따라서 클라이언트는 받은 응답을 요청한 순서대로 매치시키면 된다.
참고자료 : Parallel Connections, HTTP 1.1 Keep-Alive 기능에 대해, HTTP Pipelining: A security risk without real performance benefits, w3c protocols 8.1.2.2 Pipelining
Request 줄이기
위의 내용에 따르면 여러가지 방법으로 connection 수립에 따른 오버헤드를 줄일 수는 있지만, request와 response자체를 처리하는 비용도 있으므로, request가 많아질 수록 성능이 저하되는 것은 여전히 사실이다. 이를 줄이기 위한 몇몇 대표적인 방법이 있다.
CSS Sprite 기법
웹페이지에 여러개의 이미지를 사용할 때, 이미지 하나하나는 각각의 리소르 요청을 통해 서버에서 받게 된다. 이러한 요청을 묶어서 처리할 수 있다면 성능향상에 훨씬 도움이 될 것이다.
네이버 아이콘 이미지 파일 이 링크는 네이버 홈페이지 연결시 브라우저가 다운받은 이미지이다.
{kind=link}
이미지를 살펴보면 네이버 웹페이지에 사용되는 수많은 아이콘이 하나의 이미지에 다 들어가 있다. 각각의 이미지를 img 태그로 삽입하기보다 이렇게 합쳐진 이미지를 css background-image 속성을 이용하여, 배치하고 해당 엘리먼트의 width, height, backgorund-positoin 속성을 이용해서 적절히 crop해서 사용하면 하나의 이미지파일로 여러개의 이미지가 사용된 것과 같은 효과를 줄 수 있다. 이것을 CSS Sprite 기법이라고 한다.
아래는 CSS Sprite를 이용해서 위의 이미지 파일로부터 하나의 버튼을 나타내는 예이다.
Javascript, CSS concating & minifying
javascript나 css파일은 가독성을 위해서 공백이나, 줄바꿈, 주석등 실제 렌더링에는 관계 없지만 용량을 차지하는 많은 부분이 있다. 또 여러개의 파일에 나누어져 있는 코드를 하나로 합쳐도 동일하게 작동하기 때문에, 소스를 합쳐주고 압축해주는 기능을 하는 툴들이 있다.
대표적으로 grunt 를 통해서 작동하는 use-min 플러그인이 있다.
일반적으로 웹사이트 방문시 ~.min.js 식의 파일들은 minified 된 js파일이다. 최근에는 가독성이 떨어지는 minified 된 소스를 디버깅 하기 위해 sourcemap 을 활용하는 방법도 있다.
Javascript, CSS 파일의 위치
javascript 파일을 웹페이지의 상단에 위치시킬 경우, 해당되는 js 동작을 완료하기 전에는 그 아래 부분의 html 파싱이 멈춰버리므로, 페이지 로딩에 문제가 될 수 있다. 따라서 js파일은 가급적 페이지 하단, body 태그를 닫기 전에 위치하는것이 좋다.
반면, css 파일은 페이지 하단에 위치할 경우, css 파일이 로드되기 전까지 렌더링이 깨져보일 수 있으므로 가능한 페이지 상단, head태그 안쪽에 로딩해야 한다.
Backend Cache
backend에서도 disk에 대한 access를 줄이기 위해 리소스를 메모리에 올려놓거나, DB access를 통해 생성되는 동적인 페이지라 하더라도, 변경이 잦지 않은 경우, 미리 렌더링해 두고 사용하면, DB access나 비즈니스 로직에 따른 부하를 줄일 수 있어 캐시 사용에 따른 성능향상을 노릴 수 있다.
Cache되는 데이터의 성격
캐시 역시 자원을 소모하므로, 모든 데이터를 캐시할 수는 없다. 주로 변경이 자주 일어나지 않고, 사용자에 의해 요청이 빈번히 일어나는 데이터 위주로 캐시하게 된다. 이러한 데이터를 선별하기 위해서는 다음의 방법들이 사용된다.
-
LRU(Least Recently Used) 접근한지 가장 오래된 자원을 캐시에서 해제하는 방법이다. 이 방법은 최근에 접근한 데이터는 다시 접근이 일어날 가능성이 높다는 가정 하에 효과적이다.
-
LFU(Least Frequently Used) 접근 빈도가 가장 낮은 자원을 캐시에서 해제하는 방법이다. 이 방법은 자주 접근이 일어나는 데이터는 앞으로도 다시 접근할 가능성이 높다는 가정 하에 효과적이다.
-
First In First Out(FIFO) 가장 오래전에 캐시된 자원을 캐시에서 해제하는 방법이다.
Cache Libraries
각 언어별로는 다음의 캐시 라이브러리가 존재한다.
- Java : Guava
- Node.js : Connect-cache
- Python : Beaker